


Signaling a tectonic shift in the transformation layer
Signaling a tectonic shift in the transformation layer
And why transformation ❤️ metrics


Two major events transpired in the data world last week:
Looker + Tableau announced a partnership
dbt announced intent to build a metrics layer
My prediction: these are not isolated product decisions, but harbingers of a nascent, yet important secular trend—a consolidation of the metrics layer into the transformation layer (esp. if you buy Benn Stancil's take that the Looker/Tableau alliance signals that "Looker is ... doubling down on that long-standing identity [as a transformation tool]").
Below:
My ideas on why such a consolidation makes sense.
What's coming next
What dbt/transformation layers fundamentally do
dbt fundamentally does one thing: it enables analytics folks to easily create new warehouse tables to reduce repetitive work during consumption.
Before dbt: data is often redundantly pre-processed with the start of any new project. Friction in setting up reusable, version controlled downstream models (e.g. SQL operator in airflow, constructing opaque views) was too high. Effort to make new data models - effort to repeat work >> productivity gain, so people just repeated work instead.

After dbt: dbt did a simple thing: lowered the friction to reducing repetitive work and finding downstream models during consumption. Meaning more analysts started writing data models, making it easier to find tables in a more easily consumable form. Analysts were suddenly empowered to clean data once and re-use that data later, removing it as a redundant step from related workflows.
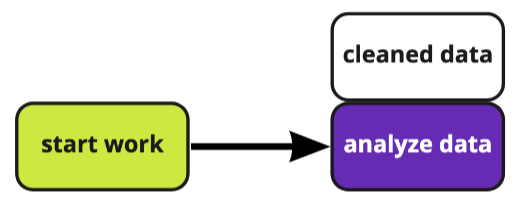
What metrics systems fundamentally do
Metrics are fundamentally another flavor of the same idea: removing redundant joins from a data consumption workflow. Sure they provide a SSOT for business definitions, but if that were all it did, a spreadsheet would suffice. Metrics layers introduce two abstractions to this end: measures and dimensions.
Metrics (measures) themselves are just a class of SQL (aggregations over a time series). Nothing special here. Dimensions are also just a class of SQL, but they often require joins to surface in service of the metrics themselves.
The ideal metrics layer should then enable you to compose metrics and dimensions flexibly through a global sense of subject, without having to think about the logic of composing the elements yourself (either by regularly pre-aggregating in the case of Airbnb's minerva or by building the joins for you).
Before metrics platforms: write SQL to analyze metrics, painstakingly joining tables.
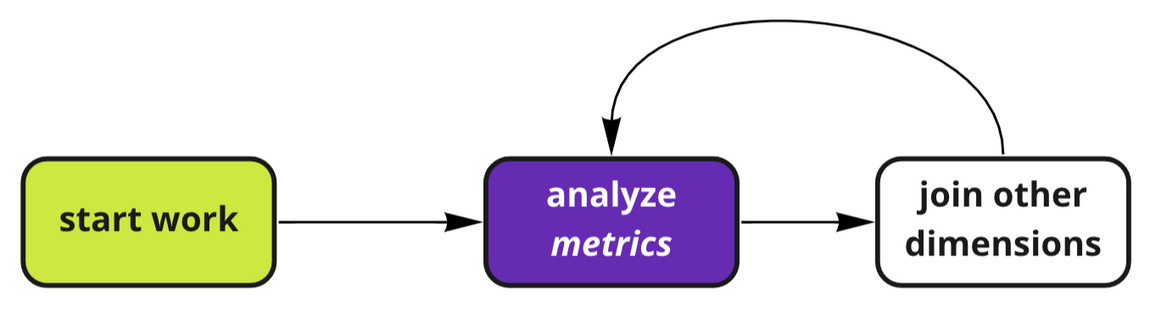
After metrics platforms: analyze data by composing pre-made measures and dimensions. Logic is predefined on how to make these joins elsewhere, or the data is all preaggregated.

I.e. pre-made dimensions and measures can now live outside of the analysis workflow, operating as separate, reusable entities, reducing redundancy the next time these metrics and dimensions need to be accessed.
Why metrics 🤝 transformation
It comes down to three things:
Metrics are really just transformations + an extra layer of logic/abstraction around how they can be composed with dimensions.
Both metrics and transformations serve a common need: reducing wasted replicate work by reducing the friction to productionize redundancies.
Putting them together would be magic.
Regarding the first point, metrics are a sub-class of dbt models. Dimensions can also be described as jinja macros (though this is a bit clunky). So there's a convenience there in that dbt is likely [with some tweaks] already architecturally well-positioned to slap some logic in and create a composable metrics layer.
Regarding the second point, metrics and transformations are philosophically quite elegantly aligned. Both basically enable you to DRY (don't repeat yourself) in SQL. Never transform twice. Never define business logic twice. While this isn’t a reason to bundle them together per se, the fact that they serve a similar purpose executed through similar means suggests that best practices employed in the implementation of one will be relevant to the other.
And finally, my last point: having metrics live alongside transformations in a single tool (or repo) has enough benefits that bundling them together is not only tenable, but preferred. Transformations are upstream of metrics, meaning that if you had a separate platform for each purpose, changes to transformations could get deployed while silently breaking downstream metric contracts. On the other hand, if your transformation tool is aware of metrics, they can be built together and tested together, so breakages can be caught before they get shipped. What’s more, consolidating these two object types allows for tighter coupling, meaning faster landing times and even interoperability between the two (imagine joining a metrics table with an upstream raw data table) — magic ✨.
What's next
There are three big, open questions here:
How will implementations mature?
From what I can tell (correct me if wrong), both Looker and dbt are missing a key part of the stack: a global sense of subjects.
By having a global sense of subject over which dimensions are defined and against which metrics (aggregations) are performed, you no longer have a scattered hodgepodge of metrics and dimensions living across different tables: you can have consolidated tables with all metrics for a subject, cut by every possible dimension.

This makes data access patterns substantially lower friction, even enabling self-service work to an extent.

What will the API look like?
Metrics are only as useful as our ability to surface them in other systems. Given the transformation world has already taken to re-injecting transformed artifacts back into the warehouse, it’d actually make a lot of sense for this to happen for the metrics layer as well, meaning any external tool would need to only access warehouse tables to consume metrics layer artifacts.
Who will open source the final form?
Transform (if it's anything like Airbnb's Minerva) is likely the closest player in developing a fully-functioning layer atm, but if there's anything we learned from dbt's world domination, people want an open solution, not a closed-source solution for their data-producing work. You don’t want a closed-source standard to ever hold your business logic hostage.
So when the dust settles, I imagine the solution will be an open source layer that ties keys to subjects, unlocking any metric to be paired with any dimension under the same subject, with the output living in the warehouse.
Who will hold the title of metric slayer?

I’m anticipating a few titillating outcomes:
dbt builds out a metrics layer (correctly, with a universal sense of subject) that becomes the standard for metric definition.
Transform open sources.
A new open source metrics platform comes out that satisfies these requirements.
Or perhaps Looker will open source its modeling layer, upsetting the balance.
I suppose only will tell where the political boundaries will be drawn.
Appendix: a convenient analogy to Hyperquery
Hyperquery is on the data consumption end of things (we do not enable productionization/manipulation of data in any shape or form — we are a doc workspace where you write reports and conduct analyses), and so our shape is different, but what’s interesting to me is that we are similarly solving DRY. Our thesis is that there is a whole class of work that cannot/need not/should not be productionized in any traditional sense (reports, adhoc work), but still deserves to be surfaced in a way that minimizes redundancies.
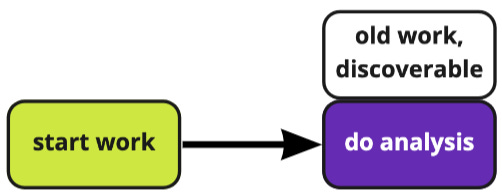
I.e. before hyperquery: at the start of work, you repeat a ton of work or end up wasting time looking for past work. One or the other is a necessary precursor to actually doing an analysis.

Post hyperquery: old work is discoverable in a centralized place, making it substantially easier to avoid repeat work.
Consequently, repeating old work no longer has to live as part of the analysis workflow, but now past work is easily discoverable during the analysis process.
To be clear, in NO way does this mean we should (or are we planning to) bundle together with transformations or metrics platforms. Past work lives in a fundamentally different place from productionized work (git), so we have no business mashing the two together. But the value prop parallels are interesting.